Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
RedMulE: A Compact FP16 Matrix-Multiplication Accelerator for Adaptive ...
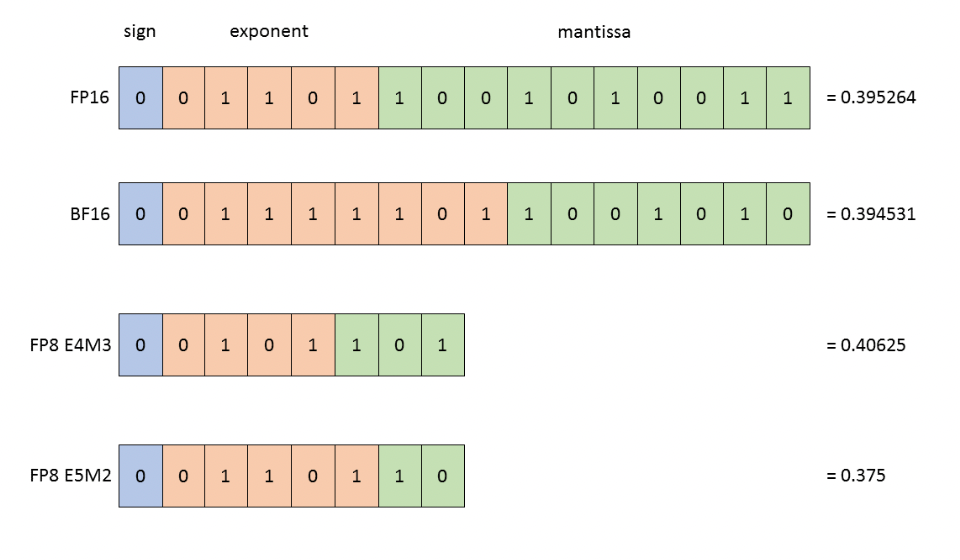
BF16 与 FP16 在模型上哪个精度更高呢 - 知乎
CUDA uses FP16 for half-precision operations - Programmer Sought
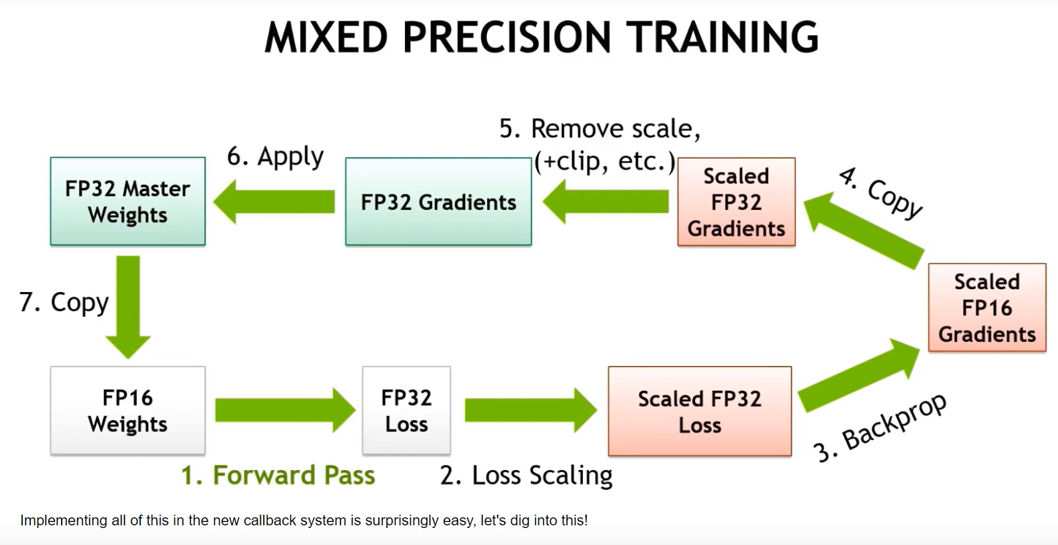
混合精度训练 | fp16 用于神经网络训练和预测 - 山竹小果 - 博客园
FP16 on embedded Jetson TX1
Simple FP16 and FP8 training with unit scaling
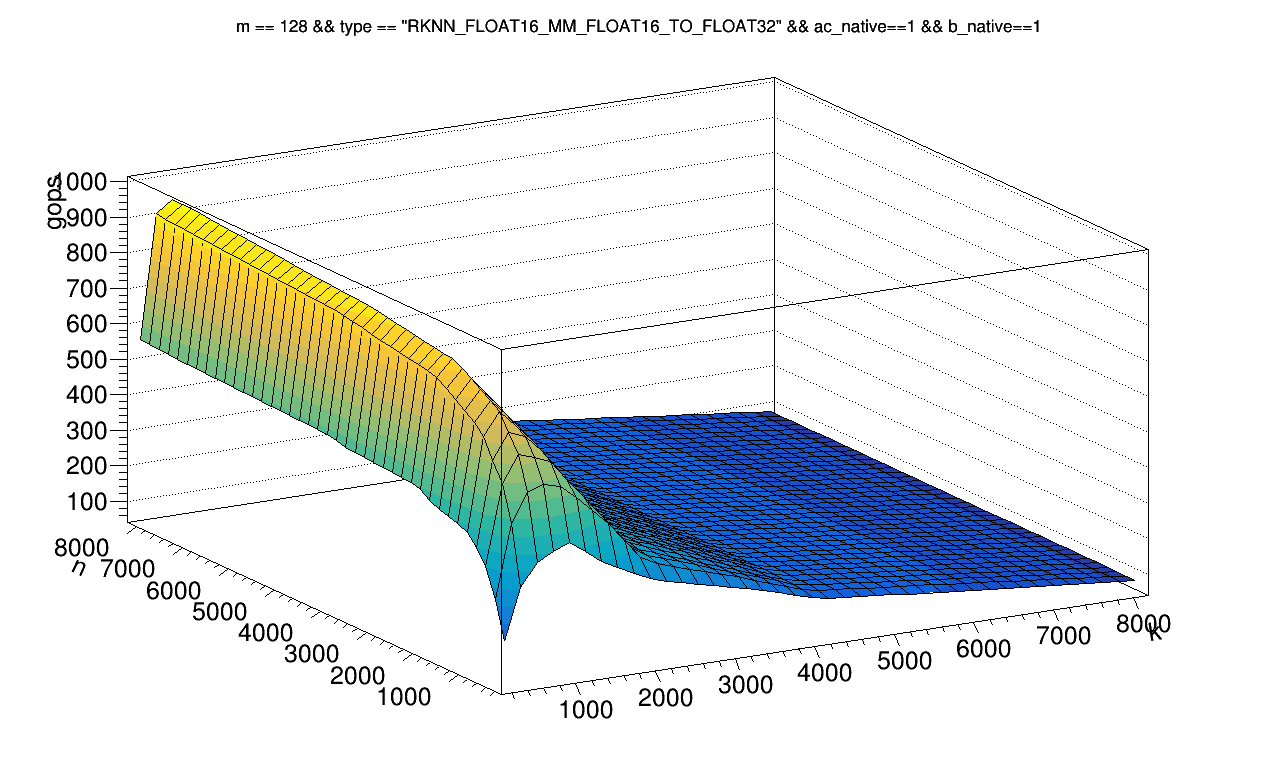
Benchmarking RK3588 NPU matrix multiplication performance EP3 - Martin ...
'cublas runtime error' for (not so large) *fp16* matrix multiplication ...
Data Types Explained: FP32 vs FP16 vs BF16 in Deep Learning - YouTube
Quantizing LLMs Step-by-Step: Converting FP16 Models to GGUF ...
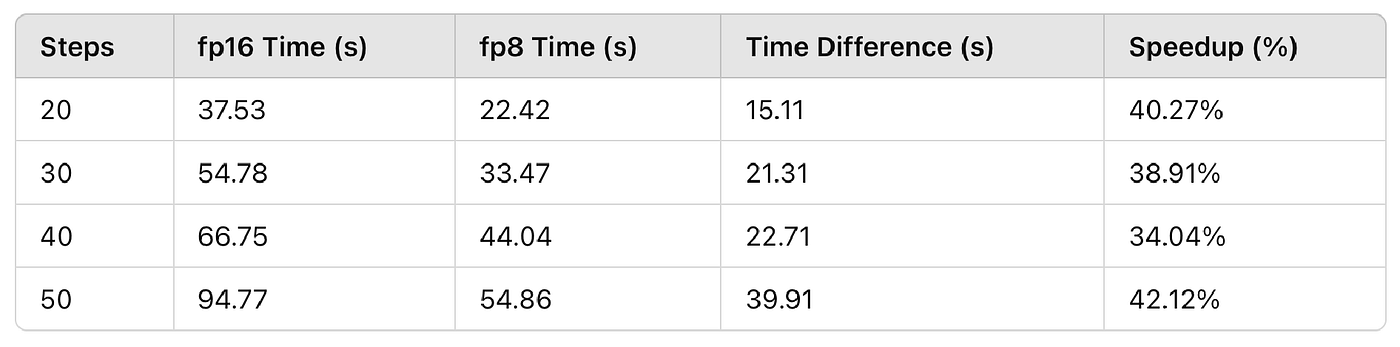
Flux.1 FP16 vs FP8 Time Difference on RTX 4080 Super in ComfyUI | Civitai
Performance of mixed-precision FP16 with FP32-accumulate matrix ...
Why BF16 is preferred over FP16 for LLM Training?
BF16 与 FP16 在模型上哪个精度更高呢【bf16更适合深度学习计算,精度更高】-CSDN博客
Guide to FP8 & FP16: Accelerating AI - Convert FP16 to FP8?
What is the difference between FP16 and BF16? Here a good explanation ...
lllyasviel/flux_text_encoders · what is the difference FP8 vs FP16 for ...
Free Multiplication Tables Printable PDFs & More! - Printables for Everyone
FP16 exponentiation approximation | Download Scientific Diagram
ValueError: FP16 Mixed precision training with AMP or APEX (`--fp16 ...
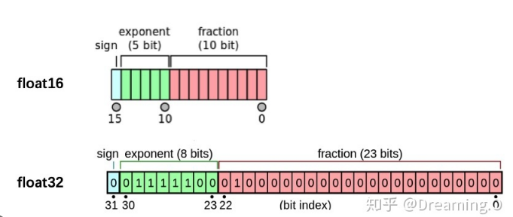
FP16 vs FP32 - What Do They Mean and What's the Difference? - ByteXD
How to use fp16 to train a model in 3.x? · Issue #11433 · open-mmlab ...
stabilityai/stable-diffusion-3-medium-diffusers · FP16 vs FP32?
FP32、FP16和INT8_atlas int8 fp16 fp32算力转换-CSDN博客
A Pipelined Fused Multiply-Add Architecture for Configurable FP16 Multi ...
How to use FP16 model precision for inference ? · openai whisper ...
16 Times Table | Multiplication Table
DESIGN OF DOUBLE PRECISION FLOATING POINT MULTIPLICATION ALGORITHM WITH ...
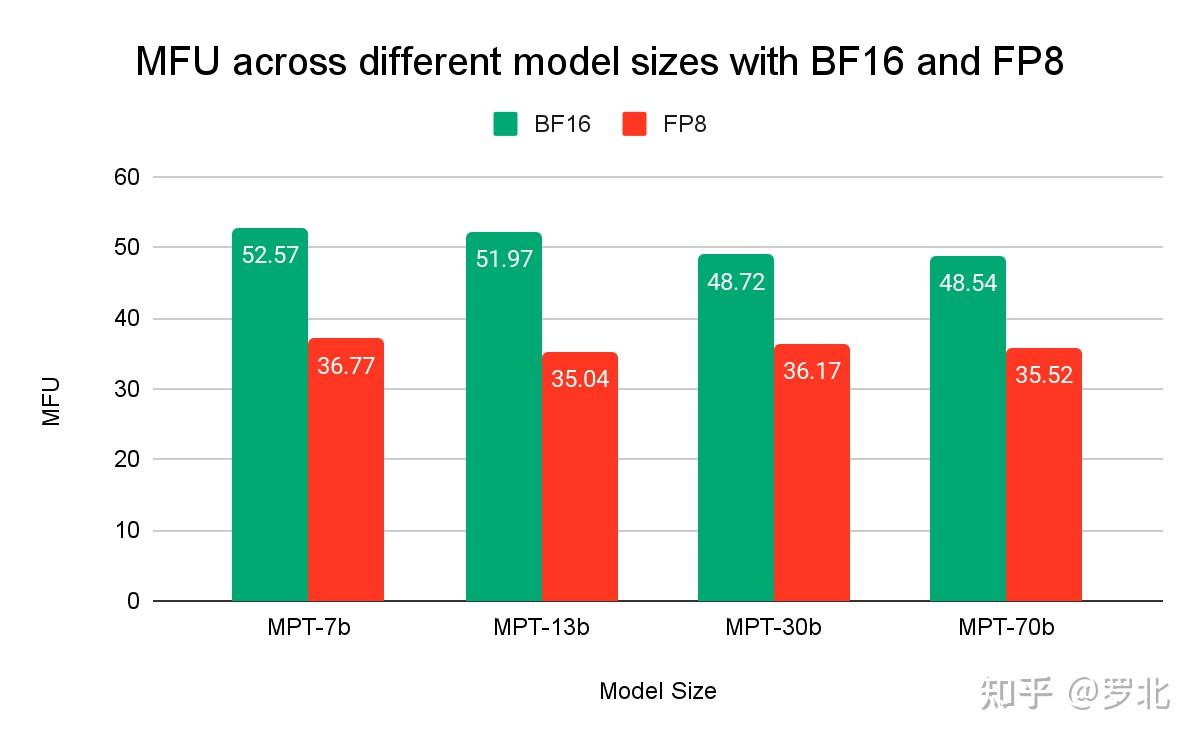
量化-Fp8 和 Fp16 的性能对比 - 知乎
DeepSpeed fp16 mixed precision converts weights to fp16 too · Issue ...
The differences between running simulation at FP32 and FP16 precision ...
An example of 32-bit FP number and FP multiplication in a... | Download ...
Understanding int8 vs fp16 Performance Differences with trtexec ...
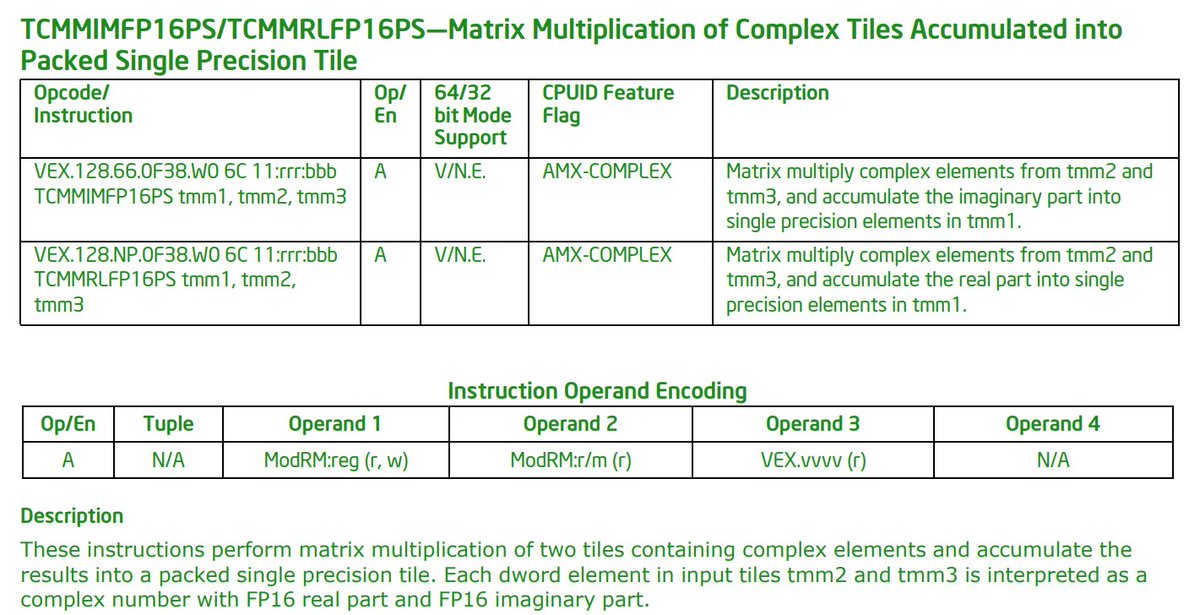
InstLatX64 on Twitter: "#Intel released the 48th edition of the ISA ...
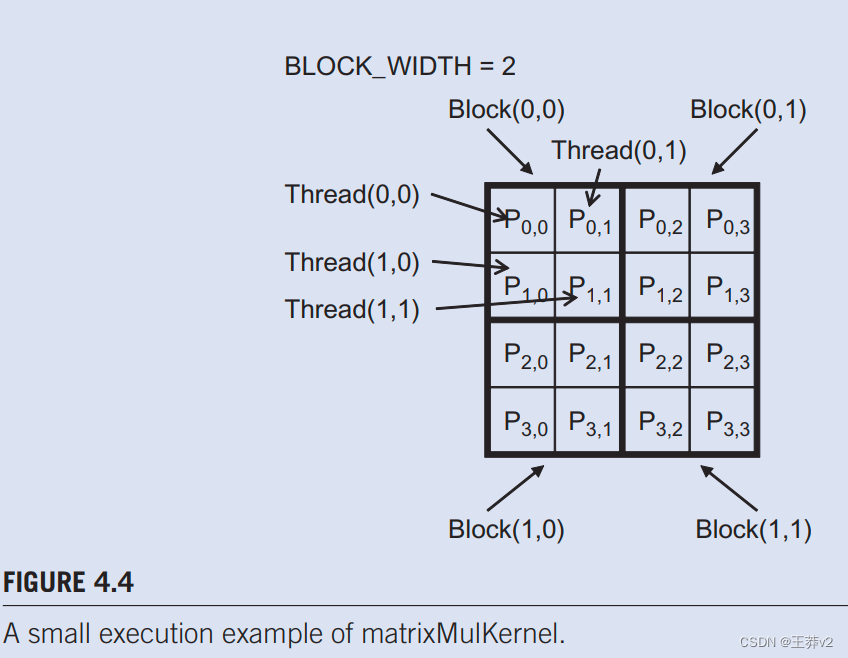
4.2 MATRIX MULTIPLICATION_fp16和int4的相乘在矩阵中是什么样子的-CSDN博客
Tensor Cores and mixed precision *matrix multiplication* - output in ...
【腾讯二面】高频考点:BF16和FP16的区别,深度解析助你通关!_fp16和bf16-CSDN博客
Cuda架构,调度与编程杂谈 - 知乎
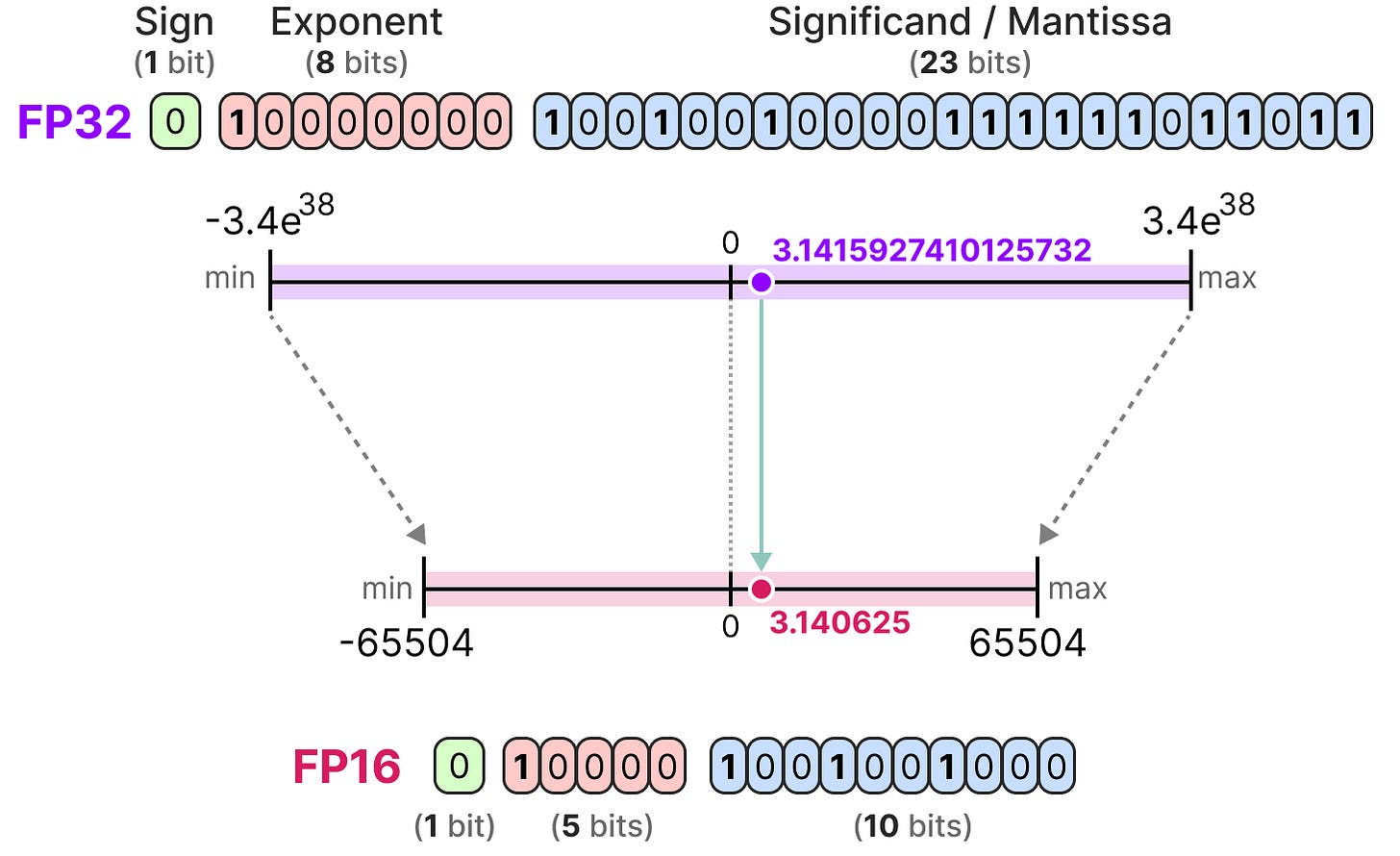
A Visual Guide to Quantization - by Maarten Grootendorst
小白必读:到底什么是FP32、FP16、INT8?-CSDN博客
GitHub - Tocule/Matrix_Multiplication_Multithreading_using_fp16
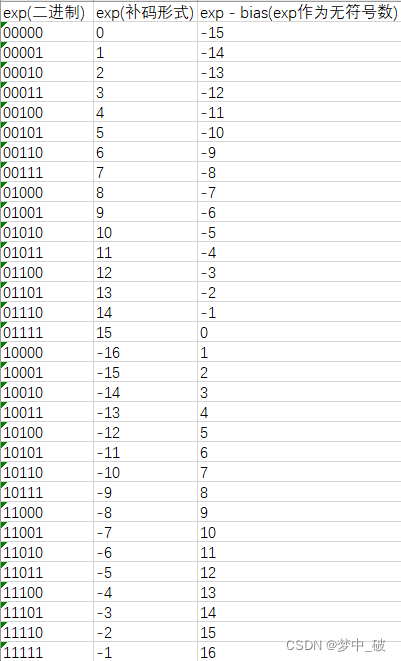
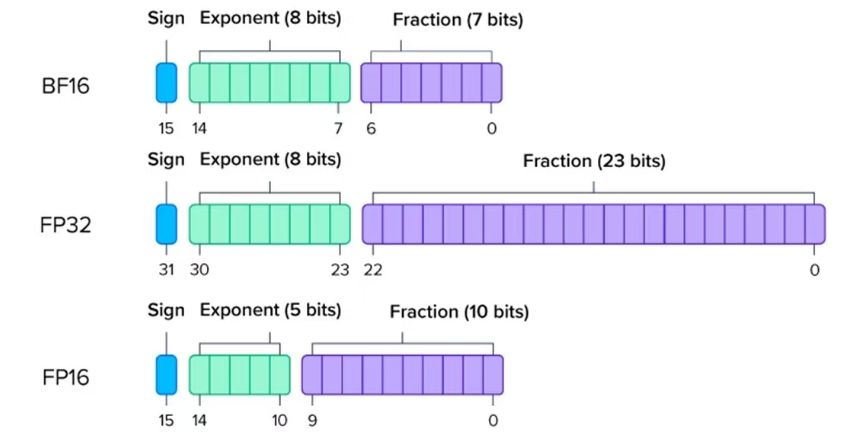
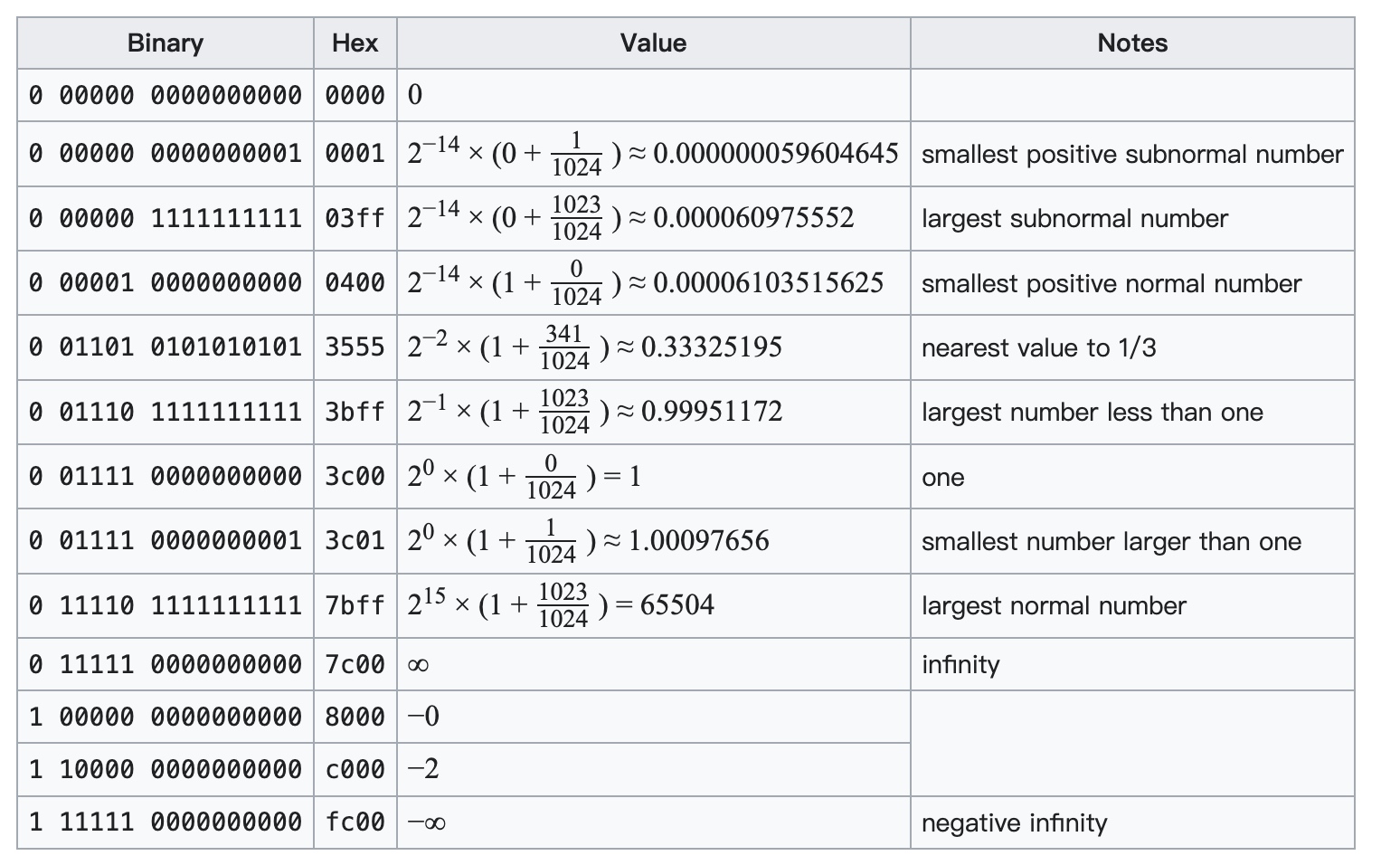
FP16数据格式详解-CSDN博客
[转]FP16数据格式详解 - 知乎
大模型中的计算精度——FP32, FP16, bfp16之类的都是什么???_混合精度训练和fp32的区别-CSDN博客
Superscalar Out-of-Order NPU Design on FPGA
混合精度 | MindSpore 1.7 教程 | 昇思MindSpore社区
fp16与fp32简介与试验_fp16和fp32-CSDN博客
TensorRT:FP16优化加速的原理与实践_tensorrt fp16-CSDN博客
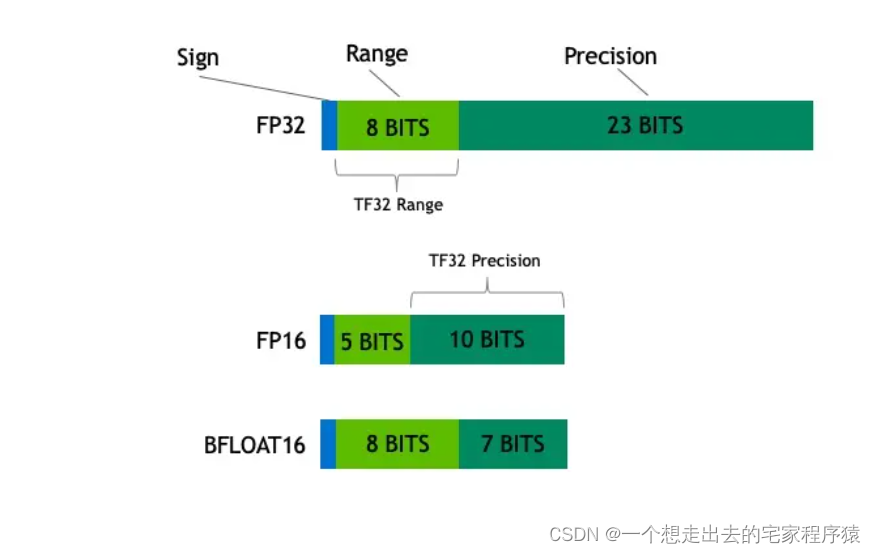
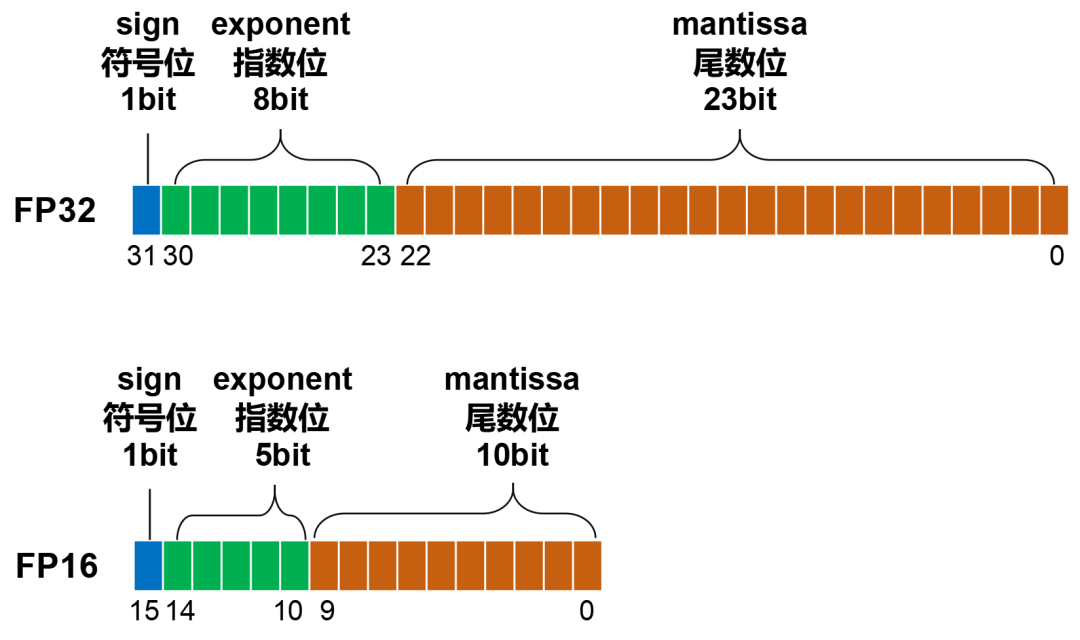
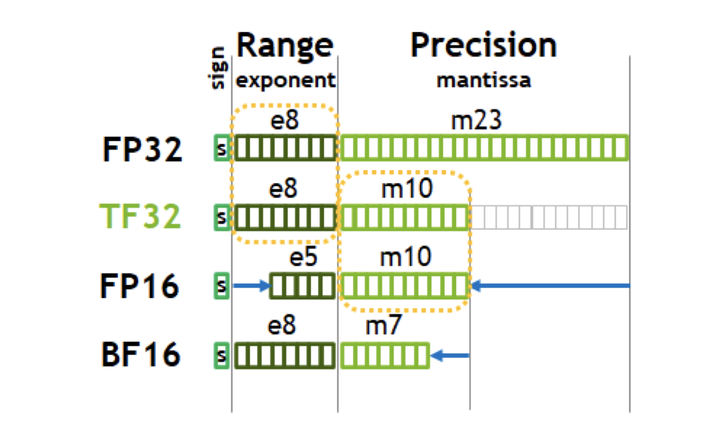
深度学习中的数据类型介绍:FP32, FP16, TF32, BF16, Int16, Int8 ...-CSDN博客
大模型开发中的浮点数精度选择:FP32、FP16、BF16详解!-CSDN博客
从一次面试搞懂 FP16、BF16、TF32、FP32 - 知乎
fp32、fp16、bf16介绍与使用_fp32和fp16算力区别-CSDN博客
Cuantización — Deep Learning Course
深入解析强化学习中的混合精度训练:FP16累加误差与Loss Scaling补偿机制-腾讯云开发者社区-腾讯云
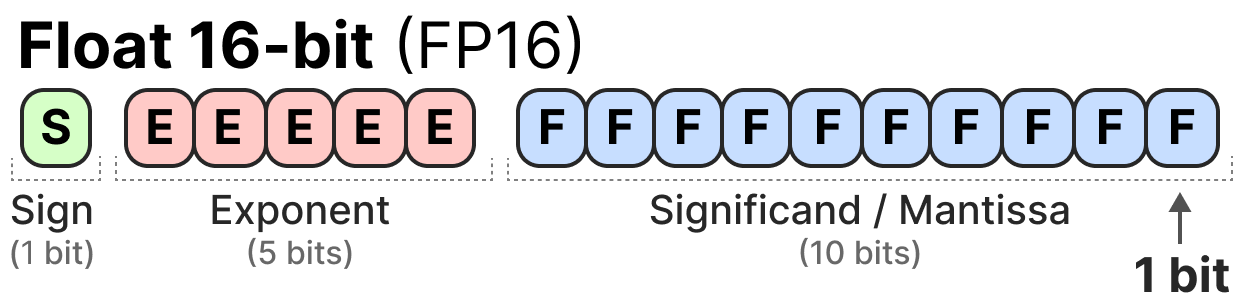
What is FP64, FP32, FP16? Defining Floating Point | Exxact Blog
Benchmarking GPUs for Mixed Precision Training with Deep Learning
FP16数据格式详解 | MLTalks
【干货】大模型算力优化全攻略——FP32、FP16、INT8数据格式精讲与实战应用_fp16和fp32-CSDN博客
BF16 vs FP16: Key Differences, Precision, and Best Use Cases
Performance comparison of our method in TF32 and FP16, cuBLAS SGEMM and ...
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
FP64、FP32、FP16、FP8简介-CSDN博客
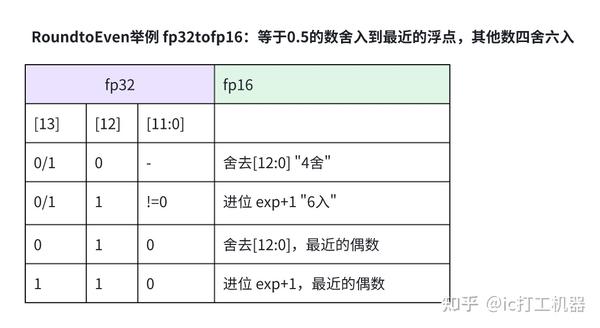
浮点FP16和浮点FP32精度互转的原理和硬件设计 - 知乎
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
一文了解模型精度(FP16、FP8等)、所需显存计算以及量化概念_fp8 fp16-CSDN博客
BF16和FP16对比-CSDN博客
您需要知道的:大模型中的算力精度FP16 vs. FP32_fp32和fp16算力区别-CSDN博客
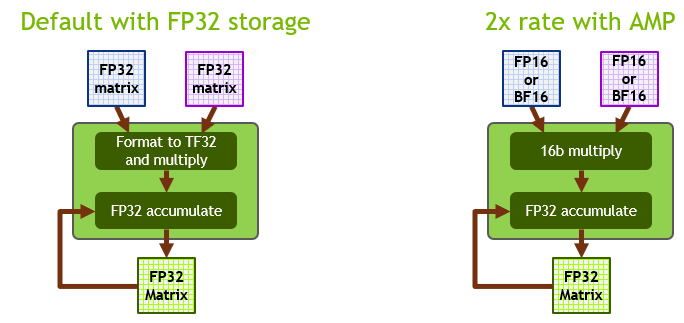
Accelerating TensorFlow on NVIDIA A100 GPUs | NVIDIA Technical Blog
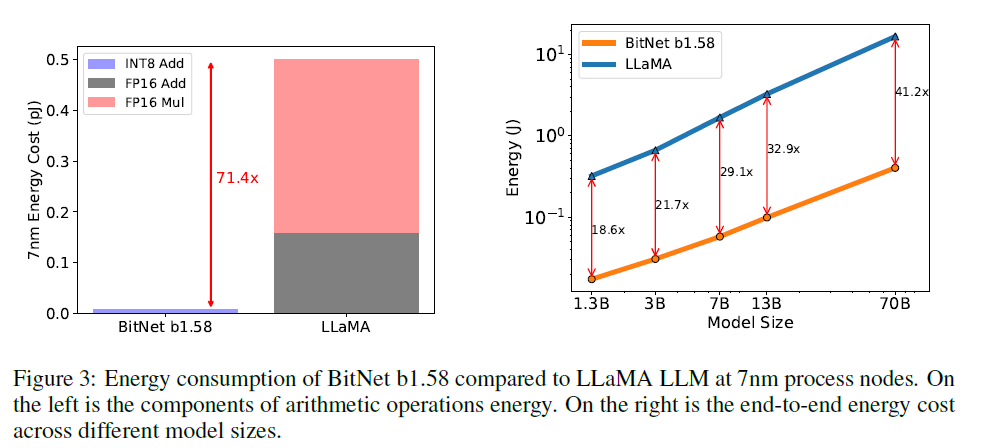
The Era of 1-bit LLMs: All LLMs are in 1.58 bits
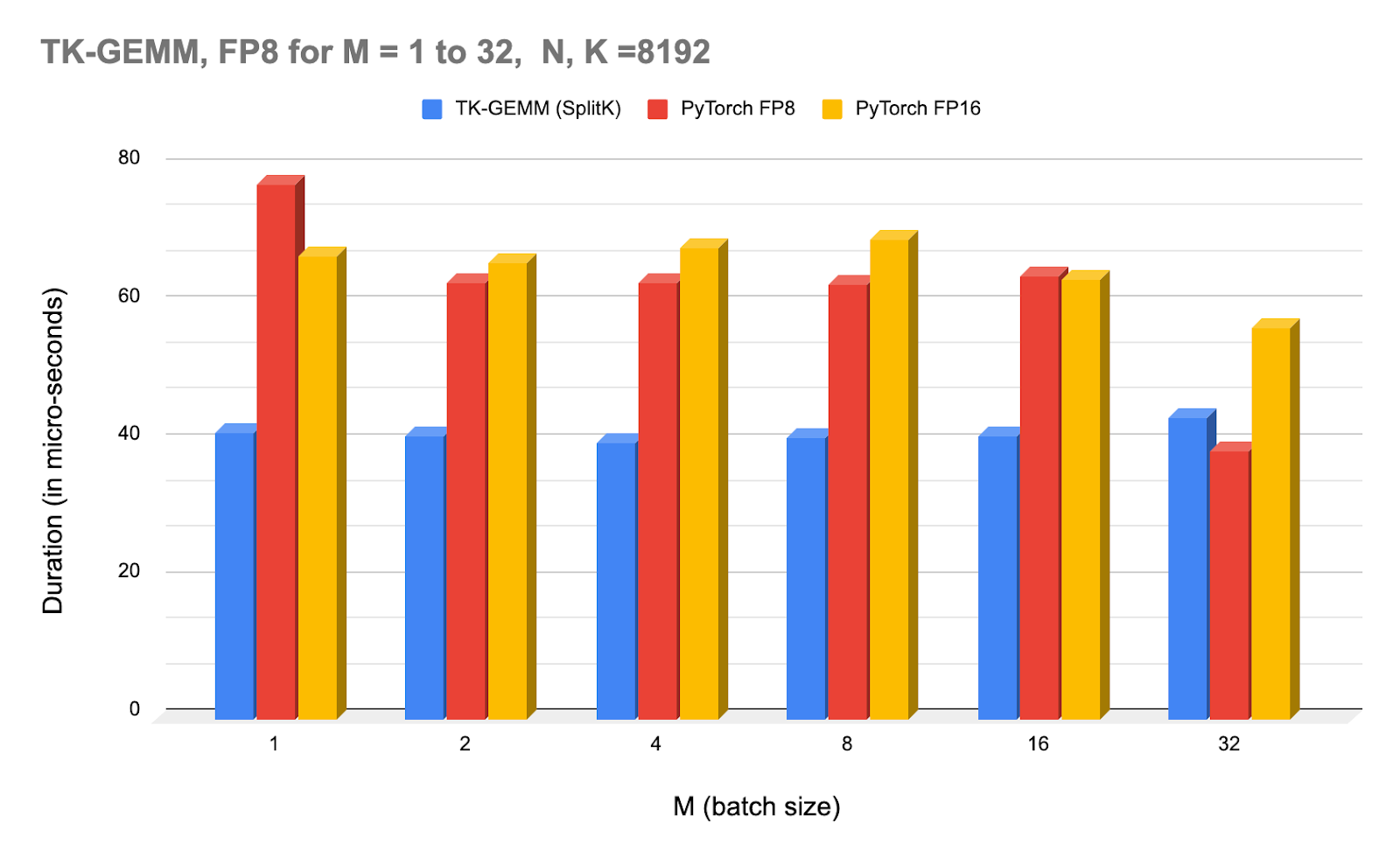
Accelerating Llama3 FP8 Inference with Triton Kernels – PyTorch
FP8 Vs BF16: Choosing Mixed Precision On NVIDIA Tensor Cores
大模型--数据类型FP16 BF16--29 - jack-chen666 - 博客园
TNN行业首发Arm 32位 FP16指令加速,理论性能翻倍 - 知乎
Quantization from FP32 to FP16. | Download Scientific Diagram
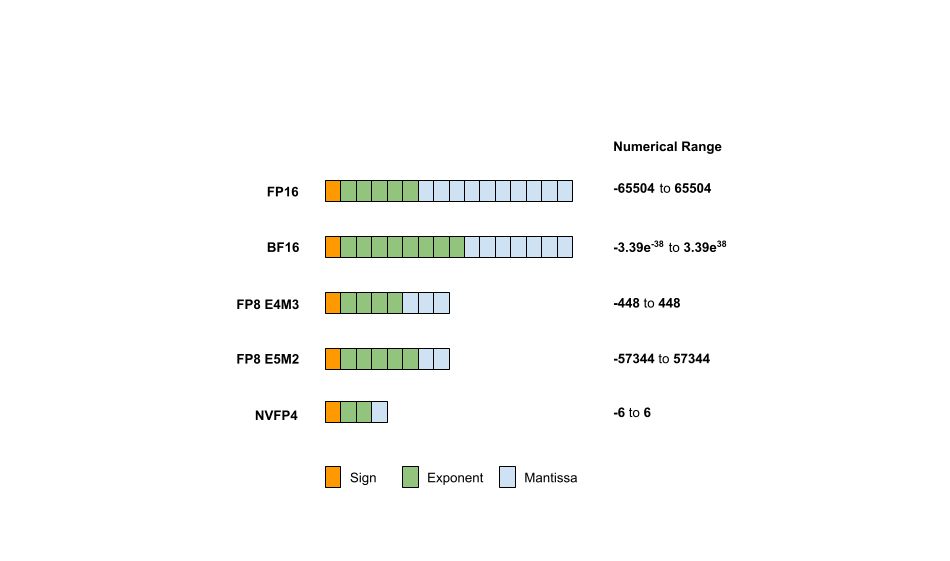
Understanding FP8 and FP4 Multiplication: A Comprehensive Guide ...
mmdetection2.X--混合精度训练(fp16 & fp32)_mmdetection 混合精度训练-CSDN博客
AMD Tech Day 2024(三):XDNA 2 AI運算架構解析,Block FP16資料類型運算效率倍增 | T客邦
sdxl-vae-fp16-fix: Image-to-Image model — overview, use cases, alternatives
机器学习-fp16表示_fp16表示范围-CSDN博客
Arm Community
FP32, FP16, BF16 и FP8 — разбираемся в основных типах чисел с плавающей ...
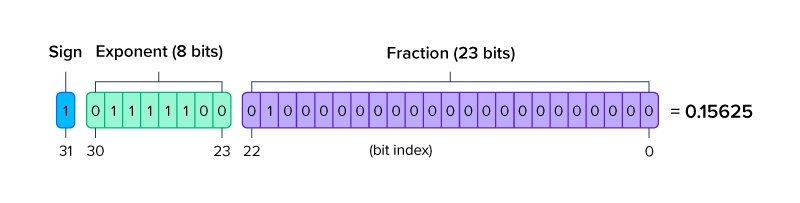
half(fp16)类型转float(fp32)类型的简单实现_fp16转fp32-CSDN博客
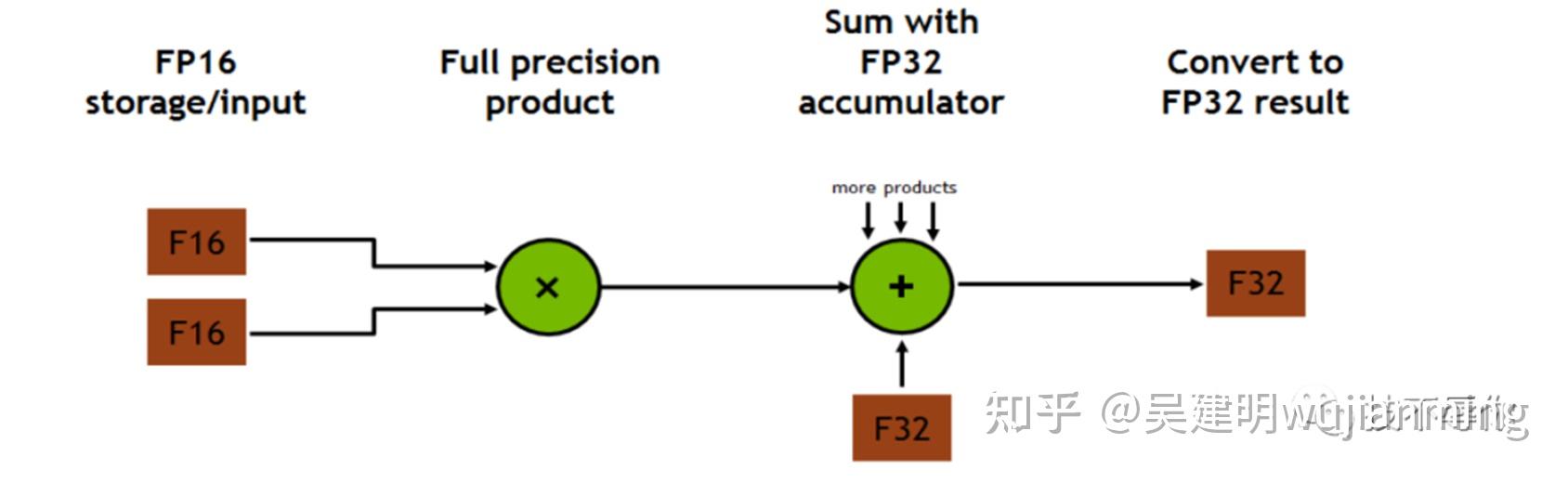
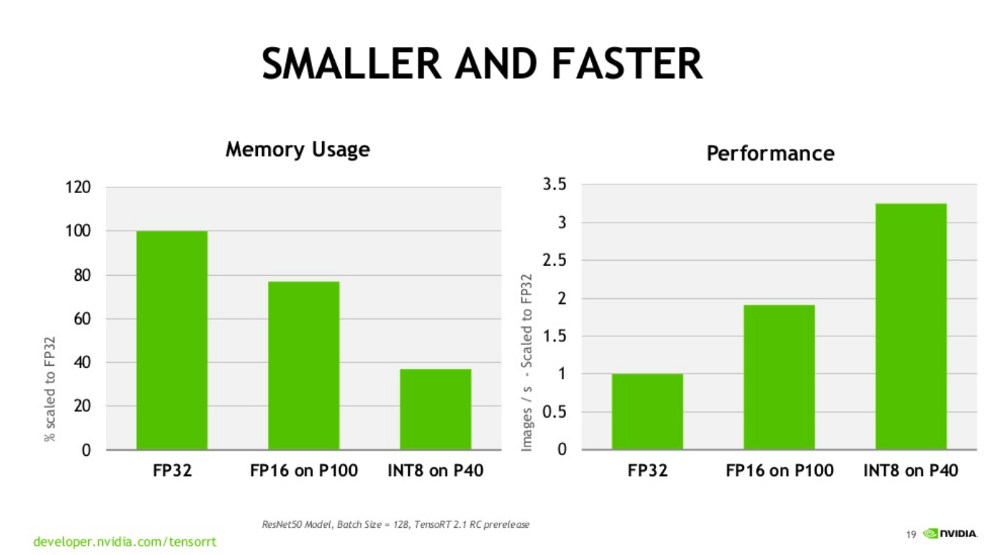
Training using half-precision floating point (fp16) can be up to 3x ...
Fast and Accurate GPU Quantization for Transformers
彻底理解大模型系列之:FP32、FP16、TF32、BF16、混合精度-CSDN博客
Floating-Point Multiply-Add RTL Design & HECTOR Verification (FP16/32/64)
FP8: Efficient model inference with 8-bit floating point numbers ...
Sea AI Lab 新研究:FP16 可以解决 RL 中的训推不一致 - 知乎
LLM RL 2025论文(二十八)FP16 RL - 知乎
Table 1 from Differential Evolution under Fixed Point Arithmetic and ...
Analysis result under FP16, BF16, and INT16 | Download Scientific Diagram
Running Llama 2 on CPU Inference Locally for Document Q&A | Towards ...
Apple Silicon deep learning performance | Page 14 | MacRumors Forums
模型精度(FP16、FP8等),所需显存计算以及量化概念! - 知乎
PPT - Lecture 10: Floating Point, Digital Design PowerPoint ...

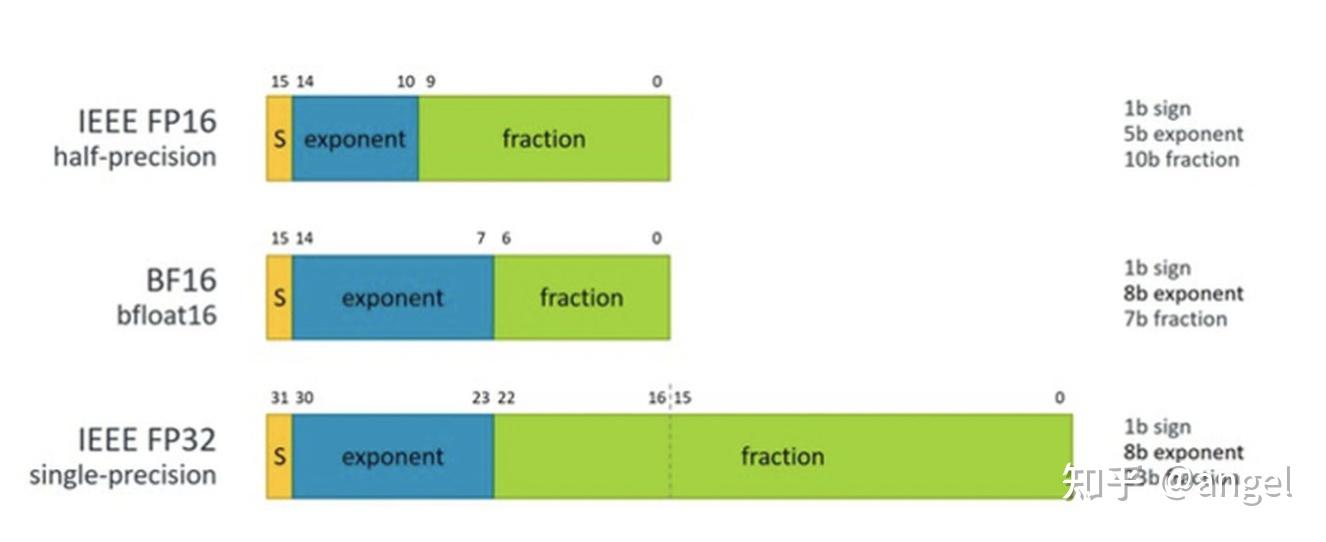
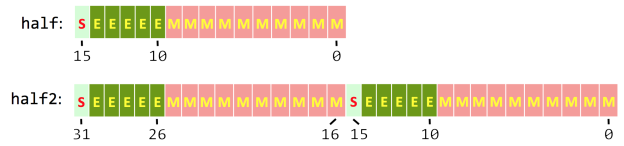
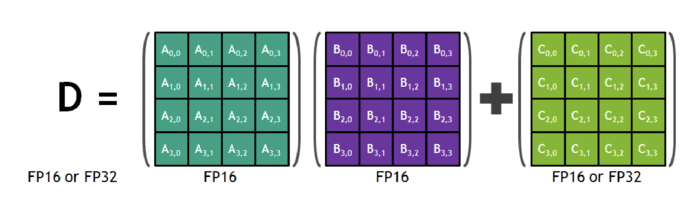
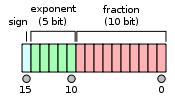
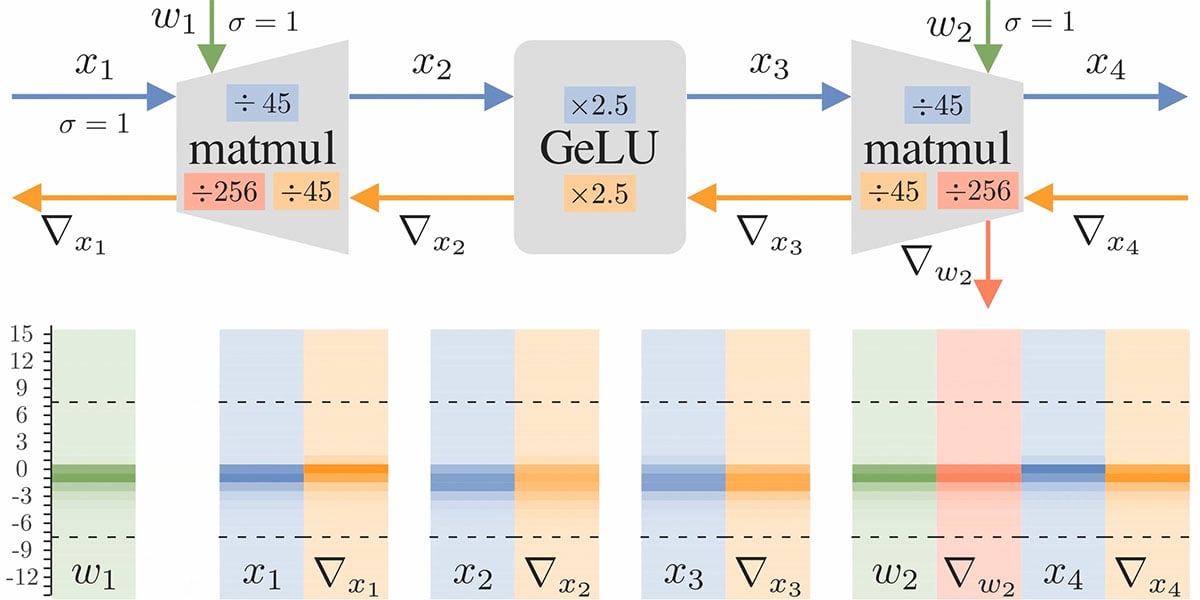







.png?width=1467&height=1485&name=Scatter%20charts%20(1).png)












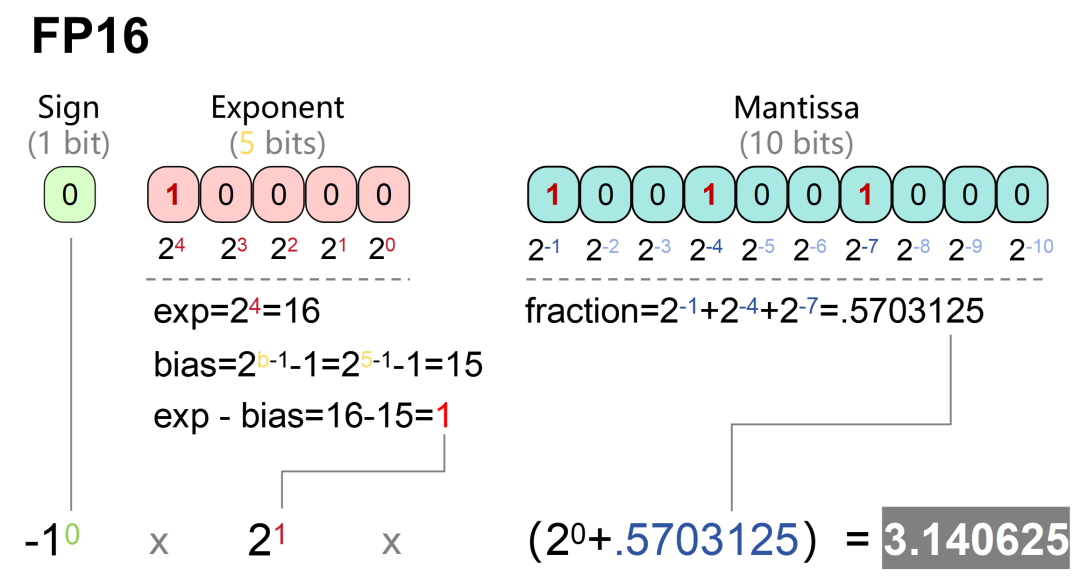
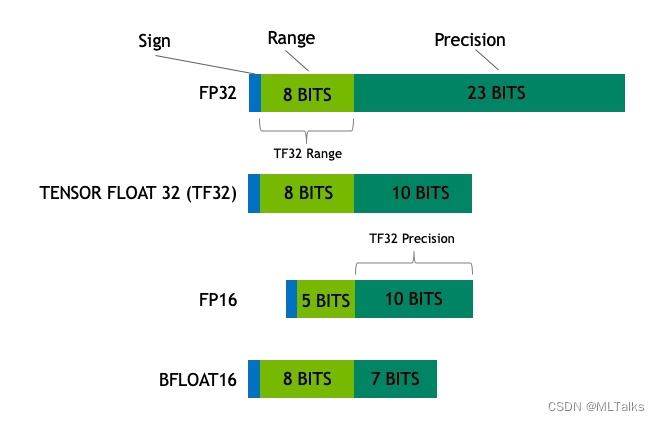
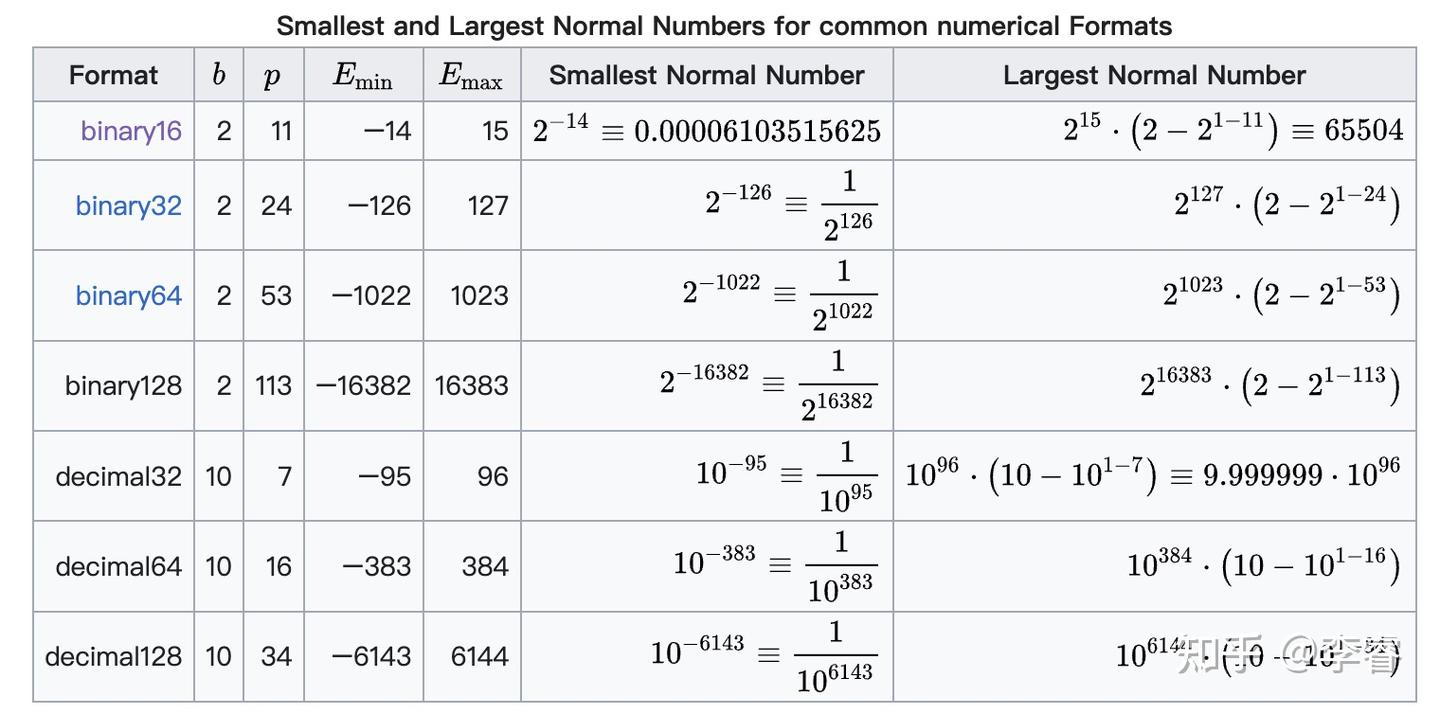
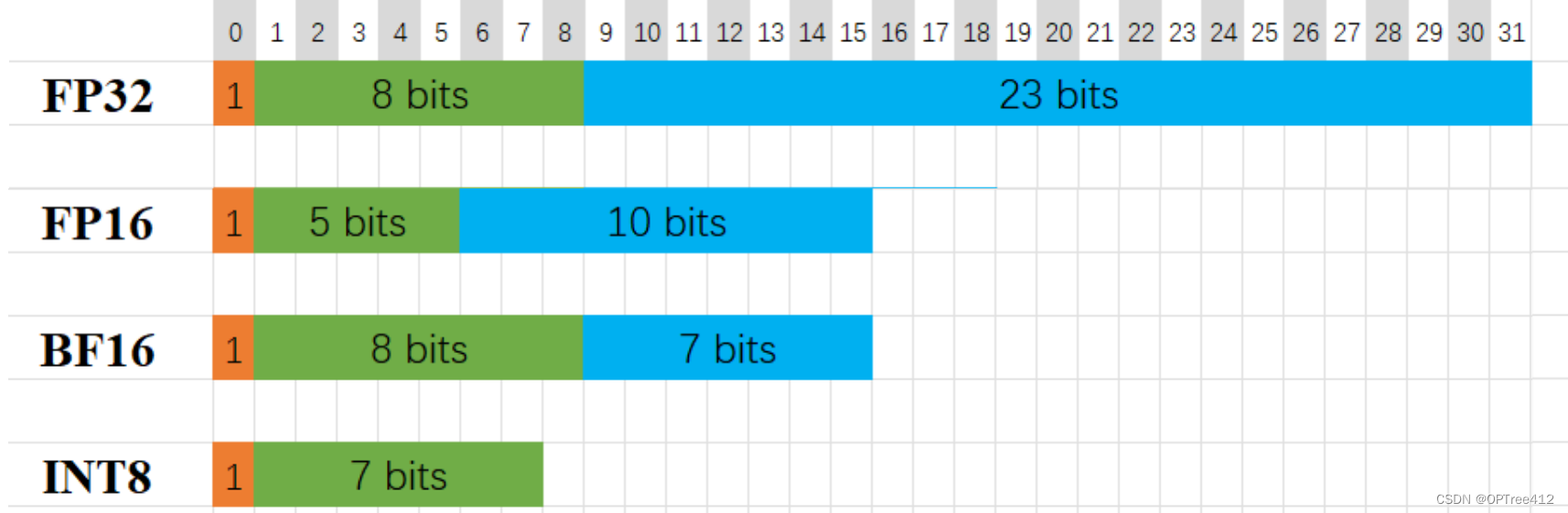

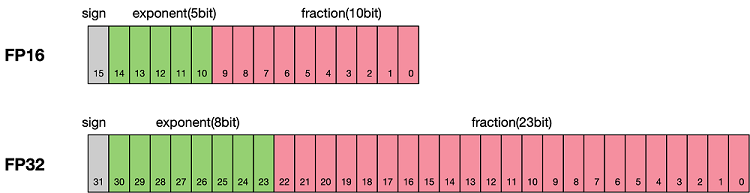
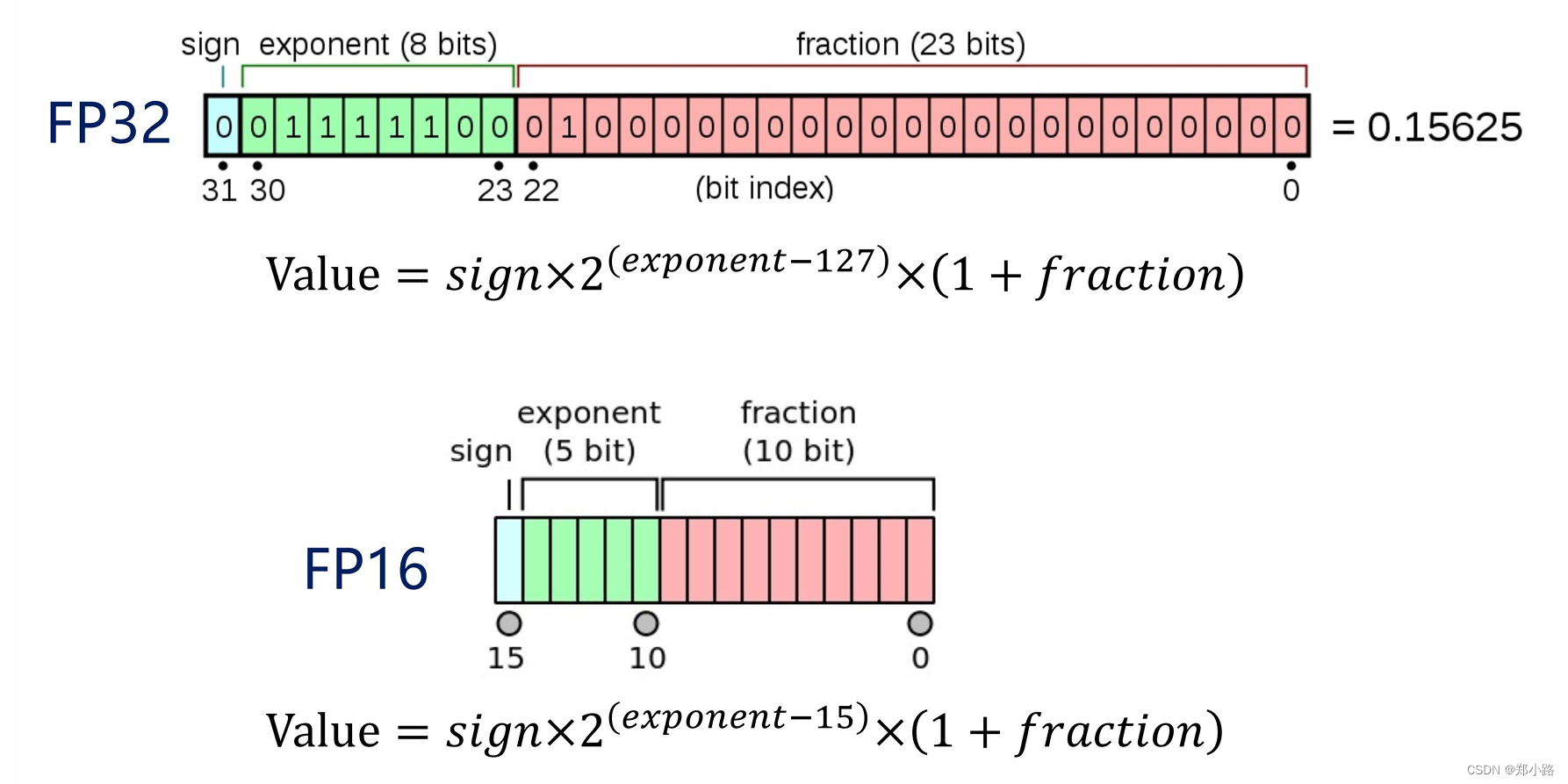

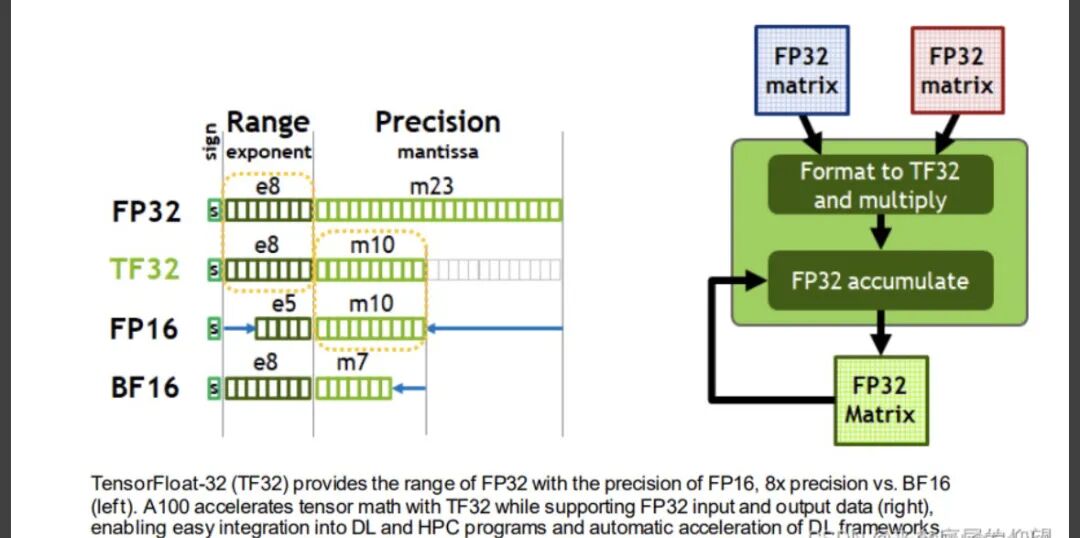
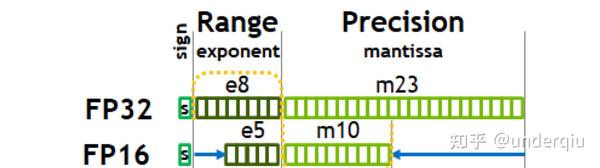




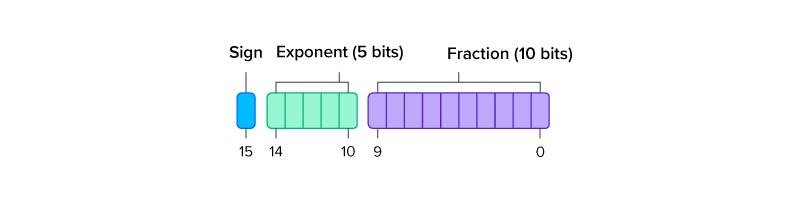
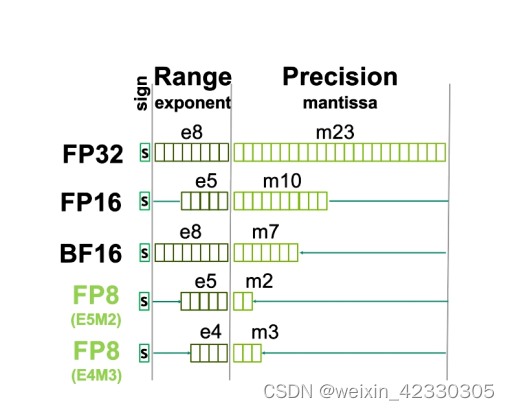




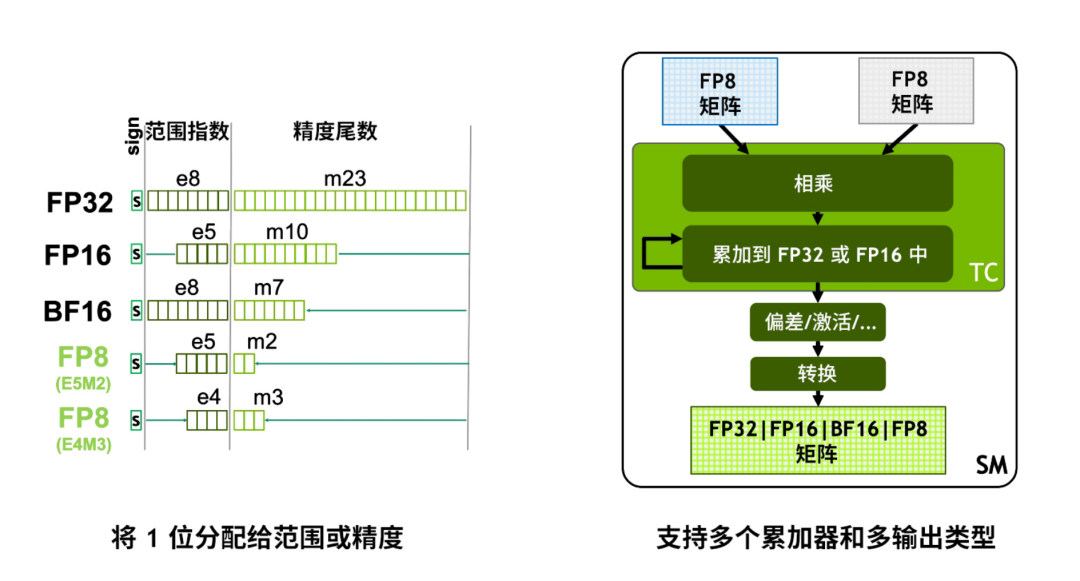


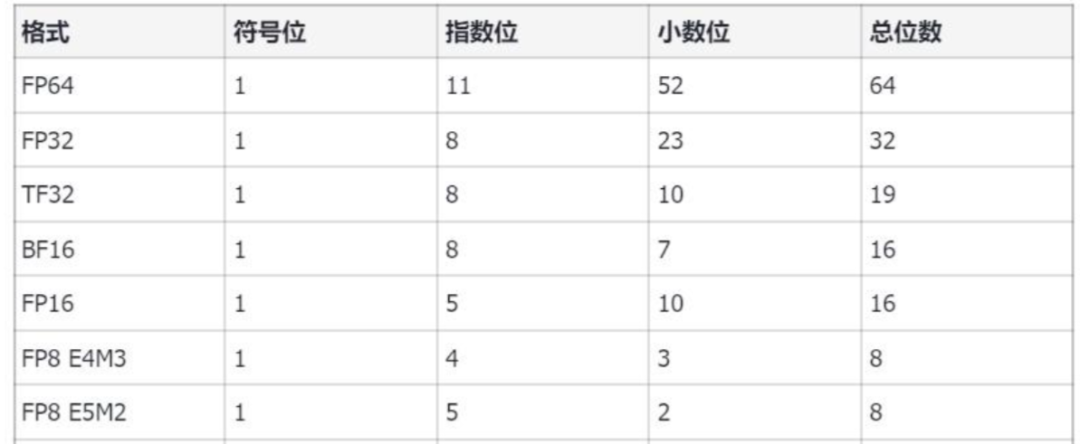



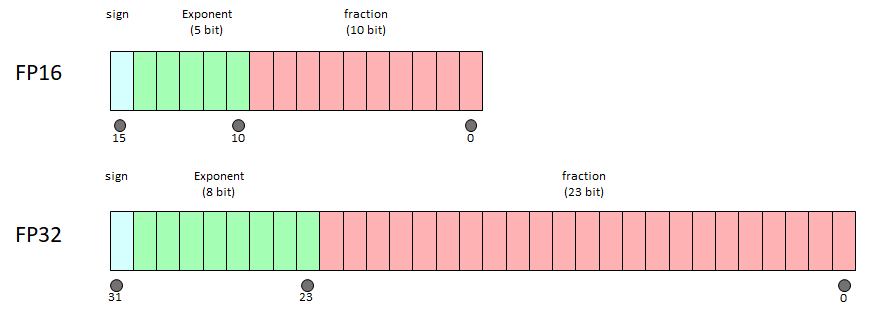


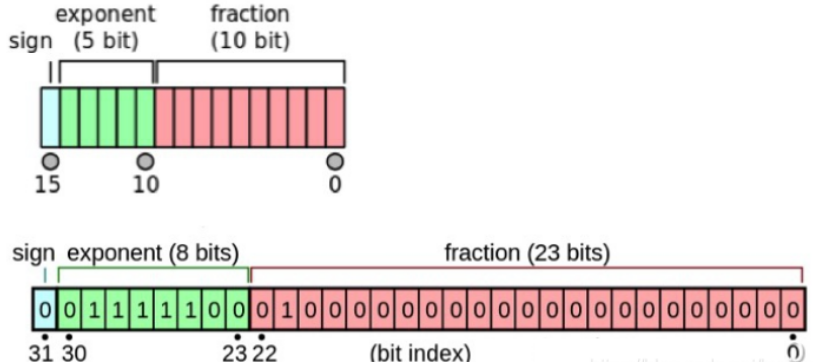

%20that%20enables%20fp16%20(half-precision)%20inference%20without%20generating%20NaN%20(Not...)